Mesterséges Intelligencia (MI) algoritmusok
(Ismertetés)
2025 október)
A MI-re sok példa létezik, például arcfelismerés, automatikus szövegjavítás, keresőmotorok, döntéshozás. A beszédfelismerő algoritmusok, a számítógépek ma már valós időben válaszolnak a mikrofonon feltett kérdésekre, legérdekesebb app a szájról való olvasás, (eszperantó, nemzetközi) az avatár-jelbeszéd lesz, a tablettgépeteknél legyintgetéssel is. Érdekes eredményeket adnak majd az MI modellek az egymás közötti kooperációi: új szakasz jelent a modellek fejlődésében a modellek egymás közötti kommunikációja, amikor bármilyen tartalmú input információ bevihető a modellekbe. A gép dönti el, igaz vagy nem igaz, hogy a saját értelemezése szerint káros vagy hasznos az új input a modell számára. Az MI rendszerek képesek lesznek saját tapasztalataikból tanulni, de a fejlesztők felügyelő, superviser szerepe megmarad: szóban közlik a modellekkel, hogy mely állítások, információk pontatlanok vagy helytelenek. 2026-ban az MI fejlődése az exponenciálisból egy stacionárius, egyenessel közelíthető szakaszba jut.
Az MI főbb algoritmus tipusai a tanító szerepe szerint, tanulás tanítóval (címkézésnek is nevezik) és tanító nélkül:
- Felügyelt tanulás (Supervised Learning)
- Felügyelet nélküli tanulás (Unsupervised learning)
- Felügyelt és a felügyelet nélküli tanulás vegyesen
- Megerősítéses tanulás (Reinforcement learning)
- Felügyelt és a felügyelet nélküli tanulás vegyesen
- Megerősítéses tanulás (Reinforcement learning)
A felügyelt tanulási algoritmusok célja az osztályozás és a regresszió.
A felügyelet nélküli tanulási algoritmusok célja a klaszterezés, a dimenziócsökkentés és az asszociációs szabály.
A megerősítéses tanulási algoritmusok olyan döntésekre összpontosítanak, amelyeket valamilyen más időpontra vonatkozóan kell meghozni, és modellalapú módszerek, valamint modellmentes módszerek tanulmányozására oszlanak.
A felügyelet nélküli tanulási algoritmusok célja a klaszterezés, a dimenziócsökkentés és az asszociációs szabály.
A megerősítéses tanulási algoritmusok olyan döntésekre összpontosítanak, amelyeket valamilyen más időpontra vonatkozóan kell meghozni, és modellalapú módszerek, valamint modellmentes módszerek tanulmányozására oszlanak.
Az egyszerűbb MI-programok csak egyszerű feladatokat tudnak elvégezni, emberi segítséggel tanulnak. Mások adatokat tudnak feldolgozni, szabályokat, mintázatokat tanulnak emberi beavatkozása nélkül.
Az algoritmus definíciója = „A bonyolult számításokat műveletek sorozatára, gépi utasítások halmazára bontjuk.” Az MI-algoritmus olyan program, utasításhalmaz, amely megmondja a számítógépnek, hogyan működjön, milyen címekről milyen adatokat töltsön be, és adjon össze. Az MI algoritmusok úgy működnek, hogy betanítási adatokat olvasnak be, amelyek segítik az algoritmus tanulását. Az adatok beolvasásának módja és címkézésének, a helyes információk megerősítésének módja jelenti a fő különbséget a különböző típusú MI algoritmusok között. Az Mi azért intelligens, mert értelmezi az adatokat.
Az adatok lehetnek címkézettek vagy címkézetlenek is, a fejlesztők által biztosított, vagy maga a program által megszerzett adatok. Vannak MI algoritmusok, amelyek megtaníthatóak önálló tanulásra, új adatok bevitelére, az egyszerűbbek a programozó beavatkozására szorulnak.

Lehetséges bemenetek: szöveg, numerikus, beszéd, kép, képlet, hang, videó, diagram, kód, EÜ fénykép, vagy pl. EKG, a kimenet lehet a felsoroltakon túlmenően nyomtató, 3D nyomtató, rajzológép is. Érdekes lesz, amikor az MI modellek egymással kommunikálnak.
Tartalomkészítés (szövegből szöveggé): A generatív mesterséges intelligencia automatizálja a cikkek és marketingtartalmak létrehozását, 40%-kal csökkentve a feladatidőt, lehetővé téve a stratégiai tervezést és a kreativitást. Design és művészet (szövegből/képből képpé): A generatív mesterséges intelligencia lehetővé teszi a művészek számára, hogy egyedi vizuális művészeti alkotásokat és terveket alkossanak, 75%-kal növelve az innovatív koncepciókat.
Szoftverfejlesztés (szövegből kóddá, kódból kóddá): A generatív mesterséges intelligencia javítja a szoftverfejlesztést a kód generálásával, a tesztelés javításával és a megoldások javaslatával, ami 30%-kal több hibaazonosításhoz és gyorsabb ciklusokhoz vezet.
Nyelvfordítás (szövegből szöveggé/hanggá): A generatív mesterséges intelligencia valós időben fordítja le a szöveget és a beszédet 95%-os pontossággal, lehetővé téve a zökkenőmentes többnyelvű kommunikációt és a globális együttműködést.
Egészségügy (képből szöveggé/képpé/diagnózis): A generatív mesterséges intelligencia segíti az orvosi képelemzést és a diagnózist, 20%-kal javítva az észlelési pontosságot a pontosabb és időszerűbb diagnózis érdekében.
Játékok (szöveg/kép játékon belüli tartalommá): A generatív mesterséges intelligencia dinamikus játéktartalmakat hoz létre és adaptálja a játékmenetet, 50%-kal növelve a játékosok elégedettségét.
Pénzügyek (szöveg/kép, szöveg, prediktív modellekké): A generatív mesterséges intelligencia 85%-os pontossággal elemzi a piaci trendeket és előrejelzi a részvénymozgásokat, 25%-kal növelve a kereskedés jövedelmezőségét.
Tanulás felügyelettel
A „Tanulás felügyelettel" elnevezés egy diák tanítása tanárral módszerre utal. A leggyakrabban használt algoritmuskategória, úgy működik, hogy egyértelműen címkézett adatokat töltünk be, a helyes választ használják tanulásra. A címkézett adatokat más adatok eredményeinek előrejelzésére is használják.
A működő felügyelt tanulási algoritmus betanításához szakértőkből álló csapatra van szükség az eredmények értékeléséhez, ás adatkutatókra, akik tesztelik az algoritmus által létrehozott modelleket, hogy kiszűrjék az MI intelligencia hibáit.
Osztályozás és regresszió
Az osztályozás egy vagy/vagy eredményt rendel minden alternatívához, bináris számrendszer használatával (0 = nem, 1 = igen). Tehát az algoritmus valamit vagy az egyik, vagy a másik osztályba sorol, de soha nem mindkettőbe. Létezik többosztályos osztályozás is, amely az adatok meghatározott kategóriákba vagy típusokba rendezésével foglalkozik, amelyek speciális igényekhez kapcsolódnak.
A regresszió azt jelenti, hogy az eredmény hozzárendelés egy valós szám (opl. valószínűség, kerek vagy tizedesvessző). Tehát van egy függő változónk és egy független változónk, és az algoritmus mindkettőt felhasználja egy lehetséges eredmény becsléséhez (akár előrejelzéshez, akár egyszerű becsléshez).
Döntési fa
A döntési fa az egyik leggyakoribb felügyelt tanuló algoritmus, faszerű szerkezetükről kapták a nevüket. A fa „gyökerei” a betanító adatkészletek, melyek csomópontokhoz vezetnek, amelyek más csomópontokhoz vezetnek, és azt a csomópontot, amely nem vezet tovább, „levélnek” nevezik.
A döntési fák az összes adatot döntési csomópontokba osztályozzák. Egy Tulajdonság Kiválasztási Mértékeknek (ASM) kiválasztási kritériumot használnak, a kritérium sokféle lehet, (néhány példa erre az entrópia, a nyereségarány, az információnyereség stb.). A gyökéradatok felhasználásával és az ASM a döntési fa a betanító adatokat al-csomópontokon keresztül követve osztályozza a bemenő adatokat, amíg el nem éri a konklúziót.
Véletlenszerű erdő
A véletlenszerű erdő algoritmus valójában különböző döntési fák gyűjteménye. A véletlenszerű erdő különböző döntési fákat épít fel, és összekapcsolja azokat a pontosabb eredmények elérése érdekében, amelyek osztályozásra és regresszióra is használhatóak.
A véletlenszerű erdő algoritmus valójában különböző döntési fák gyűjteménye. A véletlenszerű erdő különböző döntési fákat épít fel, és összekapcsolja azokat a pontosabb eredmények elérése érdekében, amelyek osztályozásra és regresszióra is használhatóak.
Vektor Gépek
A támogató vektor gép (SVM) algoritmus egy olyan gyakori mesterséges intelligencia algoritmus, amely osztályozásra vagy regresszióra is használható (de leggyakrabban osztályozásra). Az SVM úgy működik, hogy minden egyes adatot egy diagramon ábrázol (N dimenziós térben, ahol N az adatfajták száma). Ezután az algoritmus osztályozza az adatpontokat az egyes osztályokat elválasztó hiperhely megtalálásával. Több hipersík is létezhet. A hibavisszaterjesztés, vagy „a hibák visszafelé terjedése”, egy algoritmus mesterséges neurális hálózatok felügyelt tanulásnál gradiens esés segítségével. Adott mesterséges neurális hálózat és egy hibafüggvény esetén a módszer kiszámítja a hibafüggvény gradiensét a neurális hálózat súlyaihoz viszonyítva. (https://en.wikipedia.org/wiki/Backpropagation)
A támogató vektor gép (SVM) algoritmus egy olyan gyakori mesterséges intelligencia algoritmus, amely osztályozásra vagy regresszióra is használható (de leggyakrabban osztályozásra). Az SVM úgy működik, hogy minden egyes adatot egy diagramon ábrázol (N dimenziós térben, ahol N az adatfajták száma). Ezután az algoritmus osztályozza az adatpontokat az egyes osztályokat elválasztó hiperhely megtalálásával. Több hipersík is létezhet. A hibavisszaterjesztés, vagy „a hibák visszafelé terjedése”, egy algoritmus mesterséges neurális hálózatok felügyelt tanulásnál gradiens esés segítségével. Adott mesterséges neurális hálózat és egy hibafüggvény esetén a módszer kiszámítja a hibafüggvény gradiensét a neurális hálózat súlyaihoz viszonyítva. (https://en.wikipedia.org/wiki/Backpropagation)
Naiv Bayes-becslés
Azért nevezik ezt az algoritmust „naiv Bayes”-nek, mert a Bayes-tételen alapul és nagymértékben támaszkodik egy naiv feltételezésre: arra, hogy egy adott jellemző megléte nem függ az ugyanazon osztályon belüli többi jellemző jelenlétével. Ez a fő feltételezés a név „naiv” jelző értelme. A Naiv Bayes hasznos nagy adathalmazok esetén, amelyek sok különböző osztályt tartalmaznak. Sok más felügyelt tanulási algoritmushoz hasonlóan ez is osztályozási algoritmus.
Lineáris regresszió
A lineáris regresszió** egy felügyelt tanulási mesterséges intelligencia algoritmus, amelyet regressziós modellezéshez használnak. Leginkább az adatpontok, predikciók és előrejelzések közötti kapcsolat meghatározására használják. Az SVM-hez hasonlóan úgy működik, hogy adatokat ábrázol egy diagramon, ahol az X tengely a független változó, az Y tengely pedig a függő változó. Az X-Y adatok között lineáris összefüggést feltételezve, meghatározzák az egyenes paramétereket, hogy az egyenes előre jelezze a lehetséges jövőbeli adatokat.
A lineáris regresszió** egy felügyelt tanulási mesterséges intelligencia algoritmus, amelyet regressziós modellezéshez használnak. Leginkább az adatpontok, predikciók és előrejelzések közötti kapcsolat meghatározására használják. Az SVM-hez hasonlóan úgy működik, hogy adatokat ábrázol egy diagramon, ahol az X tengely a független változó, az Y tengely pedig a függő változó. Az X-Y adatok között lineáris összefüggést feltételezve, meghatározzák az egyenes paramétereket, hogy az egyenes előre jelezze a lehetséges jövőbeli adatokat.
Logisztikus regresszió
Egy logisztikus regressziós algoritmus bináris értéket (0/1) használ a független változók halmazának értékelésére, becsléséhez. A logisztikus regresszió kimenete 1 vagy 0, igen vagy nem. Erre példa egy e-mail spamszűrő. A szűrő logisztikus regressziót használ annak megjelölésére, hogy egy bejövő e-mail spam-e (0) vagy sem (1). A logisztikus regresszió akkor hasznos, ha a függő változó kategorikus, azaz igen vagy nem.

A felügyelet nélküli tanulásról általában
Adatok: a felügyelt tanulás címkézett adatokat igényel; a megerősítéses, azaz a felügyelet nélküli tanulás nem igényel.
Címkézetlen adat: ismert a helyes válasz. Tanulási jel: A felügyelt tanulás explicit helyes válaszokat kap; a megerősítéses tanulás visszajelzést (jutalmakat/büntetéseket) kap, amely gyakran késleltetett, és amelyet értelmezni kell a jövőbeli eredményeknél.
A felügyelt tanulás a bemeneteket adott, ismert kimenetekhez rendeli; a megerősítéses tanulás próbálkozással és kiértékeléssel tanulja meg, hogy mely cselekvések vezetnek a legjobb eredményekhez.
A felügyelet nélküli tanulás a gépi tanulásnál az algoritmusok címkézetlen adatokból tanulva önállóan találnak rejtett mintákat, struktúrákat. A felügyelt tanulással ellentétben nincsenek előre meghatározott eredményei a betanítási folyamatnak. A cél a bemenő adatok megismerése, például hasonló elemek osztályokba csoportosítása vagy az adatok összetettségének csökkentése. Nincsenek előre meghatározott címkék, helyes válaszok: a modell olyan adatokat kap, amelyekhez nem tartoznak megfelelő helyes kimenetek vagy címkék.
Belső struktúrák keresése:
Az algoritmus elemzi az adatokat, hogy azonosítsa az adatpontok közötti belső hasonlóságokat, különbségeket és kapcsolatokat.
Mintázatok felfedezése: Önállóan fedez fel mintákat, például hasonló vásárlási szokásokkal rendelkező ügyfelek csoportosítása vagy képekben közös jellemzők azonosítása.
Klaszterezés: Hasonló adatpontok csoportosítása. Például ügyfelek különböző csoportokba szegmentálása marketing célokra.
Dimenziócsökkentés: Az adatok egyszerűsítése a jellemzők számának csökkentésével, miközben a fontos információk nem vesznek el, ami hasznos olyan feladatokhoz, mint a képtömörítés vagy a zajszűrés.
Asszociációs szabályok tanulása: Változók közötti kapcsolatok felfedezése nagy adathalmazokban, például annak meghatározása, hogy mely termékeket vásárolják gyakran együtt egy "piaci kosár" elemzésekor.
A szabályfelismerés előnye, hogy feltár rejtett információkat: feltárhat olyan mintákat, amelyeket a szakemberek esetleg nem vesznek észre. Nagy, címkézetlen adathalmazokat kezel: alkalmas hatalmas mennyiségű adat vizsgálatára, ahol a címkézés nehézkes lenne.
Hasznos a feltáró elemzéshez, első lépésként használható az adatok megértéséhez, más technikák alkalmazása előtt. Nehéz lehet mérni az eredmények pontosságát, mert nincsenek előre meghatározott "helyes" válaszok. A felfedezett új minták megértéséhez és címkézéséhez további emberi felülvizsgálatra lehet szükség. Számos módszert használ minták keresésére. A leggyakoribb a gépi tanulás (ML) a betanításhoz. a vizsgált adatok szerint (hang/kép/írás elemzés) változnak a neurális hálózat (NN) típusok, mint például a CNN és az RNN.
Az RNN-ekben az MI biba visszaterjedést használ a saját betanításához, és nagyméretű kereséseket végez, hogy súlyok és torzítások alapján azonosítsa a mintákat. A CNN-ekben a keresés egy tiszta előrecsatolású hálózatban történik.
A megerősítéses tanulás
A gépi tanulás egy olyan típusa, ahol egy ágens úgy tanul meg döntéseket hozni, hogy egy adott környezetben cselekvéseket hajt végre egy jutalomjel maximalizálása érdekében. Próbálkozással működik, ahol az ágens pozitív vagy negatív visszajelzést kap a cselekvéseiért, és ezt a megerősítést felhasználja a legjobb stratégia felfedezéséhez, hasonlóan ahhoz, ahogyan az emberek és az állatok is tanulnak. Olyan területeken alkalmazzák, mint a játék, a robotika és az önvezető autók optimalizálása.
Az ágens és környezet: agy autonóm „ágens” kölcsönhatásba lép a „környezetével”, és minden lépésben az ágens kiválaszt egy cselekvést a lehetséges lehetőségek közül. A cselekvés után a környezet új „állapotban” „jutalmat” vagy „büntetést” kap az ágens valamilyen súlyozás szerint.
A cél, hogy az ágens egy „szabályzat” ot, -a cselekvések kiválasztására vonatkozó stratégiát – elsajátítson, amely maximalizálja a jutalom időátlagát. Próba lépésekből az ágens a jutalmakból és büntetésekből származó visszajelzéseket felhasználva tanul a tapasztalataiból, és a cselekvéseit a teljesítményének javítása érdekében módosítja explicit programozás vagy címkézett adatkészlet nélkül.
A kumulatív jutalom (vagy a sokaságátlag) maximalizálása: az ágens nem csupán a legjobb azonnali jutalmat keresi, hanem a legjobb hosszú távú eredményt, ami magában foglalhatja a rövid távú haszon feláldozását a nagyobb jövőbeli jutalmak érdekében. Az ágens olyan cselekvéseket tanul meg, amelyek végül sikerhez vezetnek, még akkor is, ha ez azonnali negatív visszacsatolással jár.
Markov döntési folyamatok (MDP): Számos megerősítéses tanulási problémát MDP-ként fogalmaznak meg, amelyek állapotok, cselekvések és jutalmak sorozatai, amelyeknél a következő állapot csak az aktuális állapottól és cselekvéstől függ.
Emberi visszajelzésből történő megerősítéses tanulás (RLHF): egy olyan technika, amelyet a modellek, például a nagy nyelvi modellek (LLP) fejlesztésére használnak, a fejlesztő visszajelzést ad a különböző kimenetekről, és a visszajelzést egy jutalmazási modell betanítására használják, amely ezután segít a mesterséges intelligenciának optimalizálni a válaszait, hogy összhangban legyenek az emberi preferenciákkal, súlyokkal.
Elméletileg a tanulás célja az általánosítás a tapasztalatokból (https://en.wikipedia.org/wiki/Machine_learning). Az általánosítás ebben az összefüggésben egy gép azon képességét jelenti, hogy egy modell pontosan teljesítsen* új, nem látott példákon/feladatokon, miután egy tanulási adathalmazon betanították. A tanulópéldák valamilyen általánosan ismeretlen valószínűségi eloszlásból származnak (amelyet az események terére reprezentatívnak tekintünk), és a tanulónak egy modellt kell felépítenie erről a térről, amely lehetővé teszi számára, hogy kellően pontos előrejelzéseket készítsen új esetekben. A gépi tanulási algoritmusok és teljesítményük számítógépes elemzése az elméleti számítástechnika egyik ága, amelyet számítógépes tanuláselméletnek neveznek közelítőleg helyes tanulási modellekkel. Mivel a tanulóhalmazok végesek, és a jövő bizonytalanságokat tartalmaz, a tanuláselmélet nem garantálja az algoritmusok teljesítményét. Így a teljesítményre valószínűségi korlátok érvényesek. Az elfogultság szórásanalízise az egyik módja az általánosítási hiba számszerűsítésének.
Az általánosításnál a jó teljesítmény érdekében a hipotézis összetettségének meg kell egyeznie az adatok mögött álló függvény összetettségével. Ha a hipotézis kevésbé összetett, mint a függvény, akkor a modell alul illeszti az adatokat. Ha a modell komplexitását növeljük, akkor a betanítási hiba csökken. De ha a hipotézis túl komplex, akkor a modell túlillesztett lesz, és az hiba nő.
*
A teljesítménykorlátok mellett a tanuláselméleti kutatók a tanulás időbeli bonyolultságát és megvalósíthatóságát is vizsgálják (https://en.wikipedia.org/wiki/Machine_learning). A számítógépes tanuláselméletben egy számítást akkor tekintünk megvalósíthatónak, ha polinomiális idő alatt elvégezhető, azaz a feladat végrehajtásának ideje polinomiális függvényként változik az algoritmus bemenetének nagyságától függően. Kétféle időbeli komplexitási eredmény létezik: P: a pozitív eredmények azt mutatják, hogy egy bizonyos függvényosztály polinomiális idő alatt megtanulható. NP: a negatív eredmények azt mutatják, hogy bizonyos osztályok nem tanulhatók meg polinomiális idő alatt. A P versus NP probléma a számítástechnika egyik legnagyobb megoldatlan problémája. Azt kérdezi és arra keresi a választ, hogy minden olyan probléma, amelynek megoldása gyorsan ellenőrizhető, az gyorsan megoldható-e. A gyors kifejezés azt jelenti, hogy létezik egy olyan algoritmus, amely megoldja a feladatot, és amely polinomiális időben fut, így a feladat végrehajtásának ideje polinomiális függvényként változik az algoritmus bemenetének nagyságától függően (ellentétben mondjuk, az exponenciális idővel). A kérdések azon általános osztálya, amelyre valamilyen algoritmus polinomiális időben választ tud adni, az a "P" vagy a "P osztály". Egyes kérdésekre nincs ismert mód a gyors válasz megtalálására, de ha olyan információkkal látjuk el, amelyek megmutatják, mi a válasz, akkor gyorsabban ellenőrizhető és megtalálható a válasz. Azon kérdések osztálya, amelyekre a válasz igazolható polinomiális időben, az NP, ami a „nemdeterminisztikus polinomidő” rövidítése. A P versus NP kérdésre adott válasz meghatározná, hogy a polinomiális időben igazolható problémák meg is oldhatók polinomiális időben. Ha kiderül, hogy P ≠ NP, az azt jelentené, hogy az NP-ben vannak olyan problémák, amelyeket nehezebb megoldani, mint ellenőrizni: ezeket nem lehet polinomiális időben megoldani, de a válasz igazolható polinomiális időben. A problémát sokan a számítástechnika legfontosabb nyitott problémájának tartják.
**
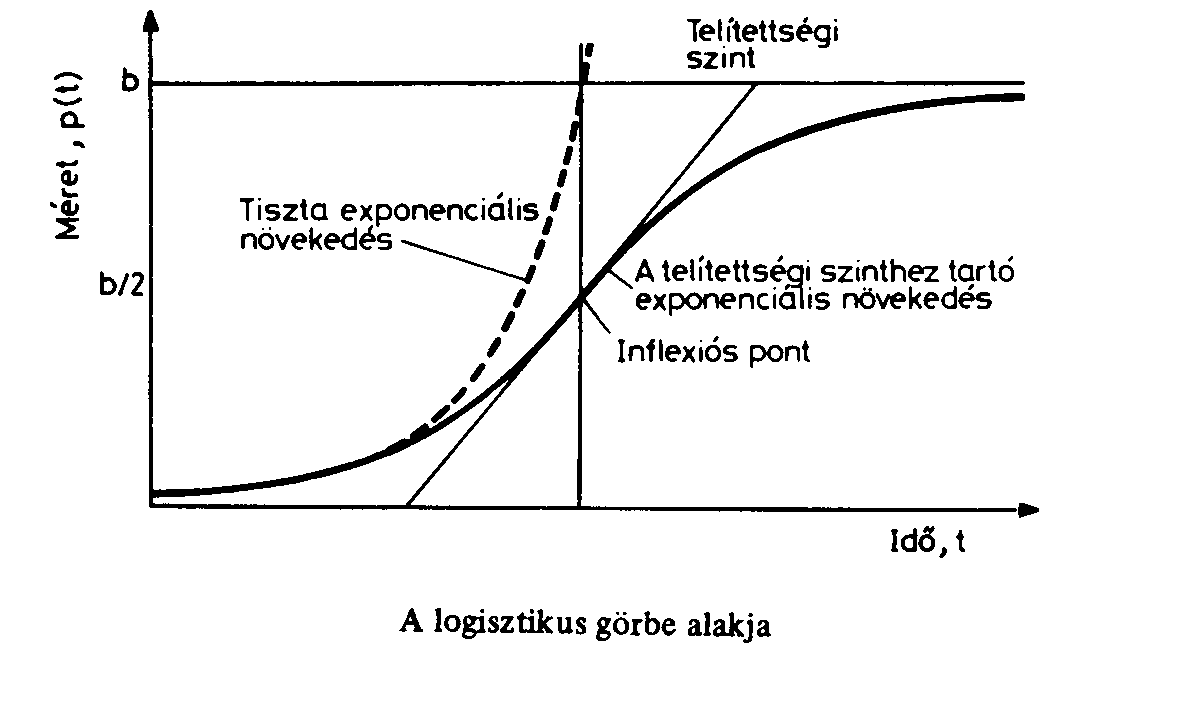
Az egyszerű trendbecslő módszerek lineáris, exponenciális, logisztikus görbék paramétereit számítják regresszióval. A logisztikus trendfüggvények olyan növekedési modellek, amelyek a növekedés lassulását és egy felső korlát elérését írják le, inflexiós pont a jellemezőjük, és magukban foglalják a Verhulst-féle, a Pearl–Reed-féle és a Gompertz-függvényt is. Ezek a függvények széles körben alkalmazhatóak, például népességnövekedés, technológiai diffúzió vagy fertőző betegségek terjedésének modellezésére, ahol kezdetben gyors növekedés, majd egyre lassuló növekedés figyelhető meg, míg végül stabilizálódik a folyamat. A logisztikus trendfüggvények matematikai modellek, amelyek egy adott populációban, erőforrásban vagy jelenségben a kezdetben gyors, majd lassuló, végül pedig a telített növekedést írják le, jellegzetességük az inflexiós pont, ahol egy egyenes érintő metszi a görbét. A növekedés sebessége a telítettségi szint felé közeledve csökken.
A növekedés gyakran logisztikai görbét követ, mint a folyamatok általában a természetben. (https://en.wikipedia.org/wiki/Logistic_function, https://hu.wikipedia.org/wiki/Szigmoid_f%C3%BCggv%C3%A9nyek ). Számos természeti folyamat úgy zajlik le, hogy az időben, egy kezdeti értéktől gyorsulva indul, majd lassulva közeledik a végső állapotig.
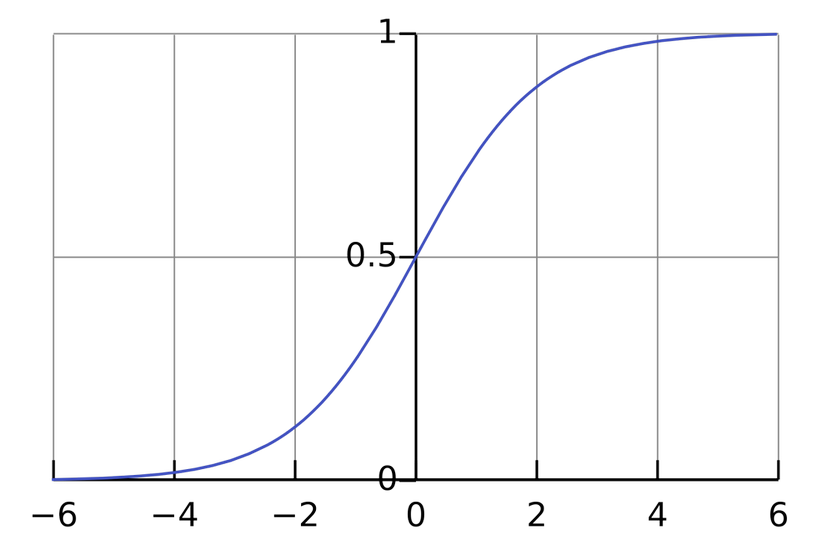
Logisztikus görbe, az origó felett van az inflexiós pont.
(Az infelxiónál a leggyorsabb az emelkedés, https://en.wikipedia.org/wiki/Logistic_function)
A logisztikus görbe hasznos az egységugrás függvény közelítéseként 3 értékű outputok esetén (kék ég, borult idő, felhőátvonulások), és 4 értékű outputok esetén, amikor egyik sem igaz (éjszaka is lehet), melyek még "fuzzy" logika nélkül kezelhetőek. (A 3 értékű logika olyan logikai rendszer, amelyben a kijelentéseknek nem csak két lehetséges értéke van (igaz vagy hamis), hanem egy harmadik, köztes értékkel is rendelkezik. A harmadik érték gyakran a "lehet," "ismeretlen," "nem definiált" vagy "bizonytalan" státuszt jelenti, és lehetővé teszi a logikai problémák rugalmas kezelését olyan esetekben, ahol nem egyértelműen eldönthető, hogy valami igaz vagy hamis. Különösen hasznos lehet a számítástechnikában, informatikában, a mesterséges intelligenciában és a formális logikában, ahol előfordul, hogy egy állításról nincs elegendő információ ahhoz, hogy egyértelműen megítéljük az igazságértékét. Például, egy adatbázisban egy mező értéke lehet üres, ami nem jelenti azt, hogy hamis, hanem azt, hogy nem ismert. Létezik szobahőmérsékleten működő 3 állapotú áramkör : magas feszültség (logikai 1), alacsony feszültség (logikai 0) és nagy impedanciájú állapot (Hi-Z). A nagy impedanciájú állapot nyitott áramkörként működik, leválasztva a kimenetet a rendszer többi részéről. Általában busz alapú rendszerekben használják, hogy több eszköz is csatlakozhasson egy adatvonalra. Egyszerre csak egy eszköz kimenete aktív; a többi nagy impedanciájú állapotban van.)